Feature-by-Feature Deep Dive: Why implementation matters
Standard site audit reports compiled by generalized enterprise dashboards are designed to give high-level progress indicators to non-technical stakeholders. They frequently fail to isolate structural defects because they scrape page arrays in simple batches. WebKernelAI treats website crawling as a software debugging process:
1. Standard Crawling vs. Recursive Diagnostics
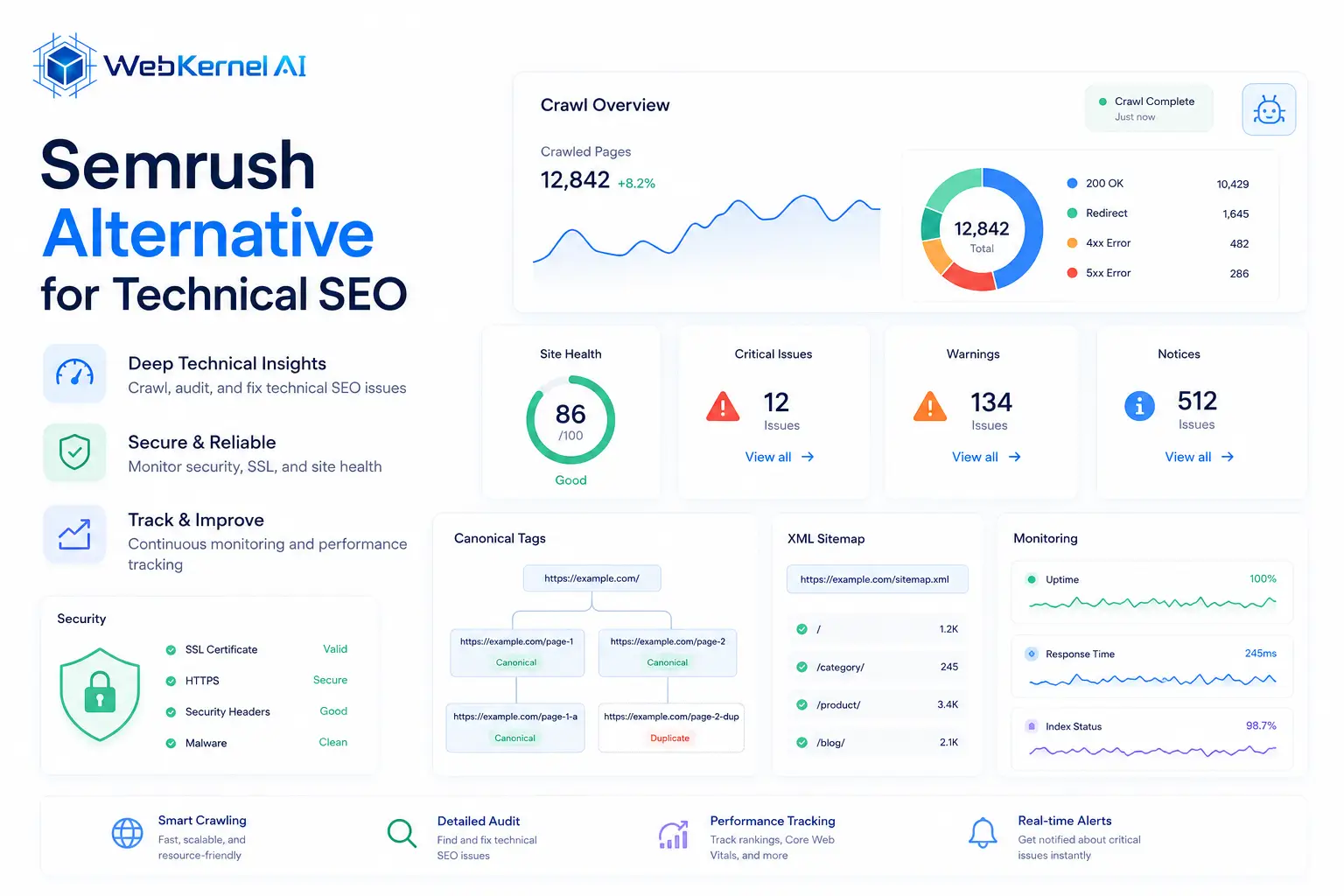
General marketing suites crawl pages linearly and flag broken assets. WebKernelAI runs recursive node parsing that charts the physical architecture of the site, letting engineers pinpoint orphaned directories, deep routing paths, and missing server headers before bailing search engine indexing runs.
2. Flattened Spreadsheets vs. Redirect Loop Tree Maps
Semrush lists redirect issues in a tabular format. When dealing with complex htaccess configurations or dynamic routing chains, simple spreadsheets cannot show the parent-child node connections. WebKernelAI isolates circular loops, multi-hop redirect chains, and PageRank leaks with visual vector mapping.
3. Standard XML Scans vs. Sitemap Intelligence
Rather than just checking if a sitemap is present, WebKernelAI performs sitemap vs. actual crawl overlap logic. We identify pages in the sitemap that return non-200 codes, detect URLs that are blocked by robots.txt but listed in the XML index, and locate high-value orphan pages completely missing from the directory mapping.
4. JavaScript SEO & Source vs. Client DOM Audits
Heavy Client-Side Rendering (CSR) often prevents search engine bots from executing scripts. WebKernelAI compares the pre-rendered SSR HTML with the dynamic client DOM after the hydration cycle, flagging missing links, hidden meta tags, and script errors bailing indexation.